
Hadoop 2.7.2 单节点与集群安装部署
Background
最近需要做一些大数据相关项目,至少需要搭建 Hadoop 的基本环境. 由于用到的是目前版本号最高的 Hadoop 2.7.2.跟文档比较多的 2.6 以下的版本相比,在部署集群的时候遇见了很多坑. 所以写一份安装指南,记录一下跌坑的过程,以示警惕.
Table Of Content
暂不讨论 Hadoop 及基于其应用的场景描述,文本只讨论基本的环境搭建步骤和与之涉及的知识点. 按照顺序总结出本文的内容节点.
-
宏观了解在集群上部署 Hadoop 的过程
-
虚拟机基本网络配置与机器配置
-
下载并解压 Hadoop
-
创建专为运行 Hadoop 的用户
-
环境变量的设定
-
修改 Hadoop 配置文件
-
启动 Hadoop 服务
-
防跌坑指南
Environment Setup
Overview: How Developer deploy Hadoop in cluster mode
通常来说,一个运维工程师是如何部署一个 Hadoop 集群呢? 集群可以当成 1 台 Master 机器和多台 Slaves 机器. 在全新的 Linux 机器群中创建 Hadoop 集群,按我的理解可以分成以下几步.
- 在 Master 上下载 Hadoop,并修改对应的 Hadoop 配置文件.
- 将修改好配置的 Hadoop 目录打包,分发到各个 Slave 中,解压到固定的执行目录.
- 修改所有机器的 hosts 文件,将局域网中的所有 ip-hostname 进行 mapping.
- 在所有机器上安装 ssh,Master 和 Slaves 之间将通过 ssh 进行运行时的通讯控制.
- 在 Master 上启动 Hadoop 服务.统一管理所有 Slave 节点.
Network and Information about Virtual Machine
因为只是实验集群的部署,所以没有用到真机. 实际上虚拟机内部的多台机器所组成的集群,其实总的 I/O 还是会被物理机器限制.
我将使用的是 1 台 Master 和两台 Slaves 三台机器都是vmware上的虚拟机,网络方式都是以 NAT 桥接具体的配置如下:
-
Master: ip:192.168.239.142 hostname:elementary-os cpu:4 core ram:16G
-
Slaves: ip:192.168.239.144,192.168.239.145 hostname:hd-worker-a,hd-worker-b cpu:1 core ram:4G harddisk:20G
P.S. Master 和 Slaves 都是基于 64 位的Ubuntu14.04.3LTS内核的 Linux. 可以视为都是通过直接安装Ubuntu14.04.3.LTS.
为了通过/etc/hosts文件通过机器名访问对应的 ip, 在每一个节点上面都修改对应的/etc/hosts文件,将集群中所有节点加到文件里面
$ sudo vi /etc/hosts
在文件底部添加以下几行(实际操作中,请将 hostname 替换成自己实际机器的 hostname 与 ip)
# Hadoop Cluster Setup
## Master
192.168.239.142 elementary-os
## Slaves
192.168.239.144 hd-worker-a
192.168.239.145 hd-worker-b
Download Hadoop
下载地址:https://mirrors.noc.im/apache/hadoop/common/current/
下载之后,会得到一个Hadoop2.7.2的解压包. 在下一步章节我们将会将其移动到其他目录.
Add Hadoop Group and User
在所有节点上都创建一个名为hduser的 user,并将其加到 sudo 列表里面. 在接下来的所有 bash 命令,默认都通过该创建的hduser来执行.
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
$ sudo adduser hduser sudo
Installing SSH and Copy Public Key to remote machine
什么是 SSH SSH (“Secure SHell”) is a protocol for securely accessing one machine from another. Hadoop uses SSH for accessing another slaves nodes to start and manage all HDFS and MapReduce daemons. Hadoop 通过 ssh 之间来通讯和管理节点之间的通讯.
$ sudo apt-get install openssh-server
TIPS: 通常来说,ssh 远程到另一台安装了 ssh 的机器上,通过ssh {username}@{hostname},之后输入密码便可以进入. 对于一些自动化部署的脚本来说自动输入密码,还需要在脚本里面写下密码. 怎么可能如此的不科学?
所以需要通过 ssh key 公钥来进行认证,达到无密码传输的过程. 假设我们需要在机器上 A 通过 ssh 远程到机器 B 且不需要密码,步骤如下:
- 在机器 A 上生成自己的 ssh 公钥与密钥
$ ssh-keygen -t rsa
此举将会在 user 目录下的~/.ssh文件夹创建对应的 id_rsa和id_rsa.pub文件. 其中id_rsa.pub就是公钥文件
- 在机器 A 上将自己的公钥复制到远程主机上
$ ssh-copy-id {username}@B
$ {username}@B password:
$ #此时输入用户密码
此举会在远程主机 B 的对应 user 的 home/.ssh 目录下创建authorized_key文件. 该公钥已经信任,拥有这个公钥的 A 主机用户可以直接通过ssh {username}@B不输入密码而直接远程到 B
OK.在了解到这一步之后,大概知道一台机器的主机需要如何配置 ssh 了. 因为在 Hadoop 集群中,Master 与每一台 Slaves 都需要进行 ssh 通讯, 所以需要在 Hadoop 中每一台机器都生成自己的 ssh 公钥,然后与 Master 互相进行公钥传输动作.
在我自己的集群中,进行了 4 次ssh-copy-id操作:
- elementary-os -> hd-worker-a
- hd-worker-a -> elementary-os
- elementary-os -> hd-worker-b
- hd-worker-b -> elementary-os
Basic Environment Setup
在修改 Hadoop 的配置之前,需要进行配置的是所有节点的环境变量设置与必要的基础程序.
JDK
Hadoop 运行在 Java 环境中,所以每个节点都需要安装 JDK. 需要保证的是确保每一台节点上安装的 JDK 版本一致. P.S 我自己是 Master OpenJDK-8 + Slaves OpenJDK-7. 目前还是正常运行的 (顺便吐槽一下 Ubuntu14.04默认的 apt-get 源,相当傻逼.在不添加自己订阅的其他源的情况下连 OpenJDK8 的地址都没有,而且如果安装 Git 之类的工具,为求稳定居然用的是 1.7 以下的版本. 这也是为什么我日常开发用的是elementary-os,虽然也是基于 ubuntu14 的内核, 但是 elementary-os 修改了其默认的 apt 源,ui 看起来也更加顺眼)
$ sudo apt-get install openjdk-7-jdk
通过此举,安装的默认的 jdk 路径是/usr/lib/jvm/java-7-openjdk-amd64. OpenJDK8 同理. OracleJDK 也推荐复制到/usr/lib/jvm目录下.(守序善良 Linux 派优雅的约定之一)
记住这里咯.在下面我们会将这个 JDK 的目录,加到当前用户hduser的.bashrc中.
Configure Hadoop
终于到了这一步. 建议首先在 Master 上机器修改好 Hadoop 的配置.然后压缩该文件夹,复制到其他 Slave 节点上的同一目录.
Unpack and move hadoop folder
假设下载好的 hadoop-2.7.2.tar.gz 在 当前用户的Downloads文件夹中. 解压完毕之后,将其移动到/usr/local下,并更名为hadoop
$ mv hadoop-2.7.2 /usr/local/hadoop
Update Environment File
在配置 Hadoop 的过程中,下列配置文件将会被修改.
~/.bashrc /usr/local/hadoop/etc/hadoop/slaves /usr/local/hadoop/etc/hadoop/hadoop-env.sh /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/mapred-site.xml /usr/local/hadoop/etc/hadoop/hdfs-site.xml
~/.bashrc
还记得之前提过的 JDK 路径吗,将其配置成JAVA_HOME 修改当前用户的 bash 配置文件,将其加到.bashrc 的底部
$ cd ~
$ vi .bashrc
#Hadoop variables
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
/usr/local/hadoop/etc/hadoop/hadoop-env.sh
还是跟上面一样,需要将 JDK 的路径设置成JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/
/usr/local/hadoop/etc/hadoop/core-site.xml
在<configuartion></configuration>之间添加一个 fs.default.name,其值为 master 机器的 9000 端口. 譬如我的 master 机器是elementary-os,则 value 是hdfs://elementary-os:9000 P.S.接下来的变量{master-hostname}请自行替换成自己的 master 的机器名.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://{master-hostname}:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop_store/tmp</value>
</property>
</configuration>
/usr/local/hadoop/etc/hadoop/yarn-site.xml
在<configuartion></configuration>之间添加:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>{master-hostname}</value>
</property>
</configuration>
/usr/local/hadoop/etc/hadoop/mapred-site.xml
mapred-site.xml默认是不存在的. 但是有一份模板文件mapred-site.xml.template,我们将其复制并重命名成mapred-site.xml
$ cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
在<configuartion></configuration>之间添加:
<configuartion>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>{master-hostname}:9001</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>{master-hostname}:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>{master-hostname}:19888</value>
</property>
</configuartion>
/usr/local/hadoop/etc/hadoop/hdfs-site.xml
在修改hdfs-site.xml这个配置文件之前,我们需要知道更多的一件事. hdfs 的块状文件,储存在一个指定的目录中. 按照官方文档的推荐,和网上一些文件夹的路径的约定,我们将这个 hdfs 的文件储存目录叫做hadoop_store.绝对路径为/usr/local/hadoop_store
于是 hadoop 的相关文件夹就变成了两个:
/usr/local/hadoop /usr/local/hadoop_store
由于读写权限问题,我们需要将hadoop_store的权限改成任意可读可写
$ sudo mkdir -p /usr/local/hadoop_store
$ sudo chmod -R 777 /usr/local/hadoop_store
然后再在配置文件里面加入
<configuartion>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>{master-hostname}:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/datanode</value>
</property>
</configuartion>
slaves
slaves文件里面存储的是作为 slave 的节点的机器名. 以行为单位,一行一个. 默认只有一行 localhost. 从一般的集群角度来说,Master 不应该担当 Worker 的角色(老湿布置作业给小学僧,自己是不会一起做作业的) 所以 slaves 文件一般只写 slave 节点的名字,即 slave 节点作为 datanode,master 节点仅仅作为 namenode.
但是由于我是一名好老湿,所以在本机配置中 master 也充当了 worker 的角色,所以本机是这样改的:
elementary-os
hd-worker-a
hd-worker-b
致此,所有的配置文件已经修改完毕. 可以将 master 上的 hadoop 文件夹压缩并且分发到各个 slave 节点上.
Last Configure : Format Namenode
最后一步配置,初始格式化 hdfs
$ cd /usr/local/hadoop/
$ hdfs namenode -format
Start all Hadoop deamons
启动 Hadoop 服务.
$ su hduser
$ cd /usr/local/hadoop/
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
如果启动成功,在 master 节点上通过 jps 命令查看,应该包含如下 hadoop 进程
hduser@elementary-os:~$ jps
51288 Jps
22914 ResourceManager
22361 NameNode
23229 NodeManager
22719 SecondaryNameNode
在 slave 节点上通过 jps 命令查看,应该包含如下 hadoop 进程
hduser@hd-worker-a:~$ jps
6284 NodeManager
6150 DateNode
6409 Jps
或者可以通过浏览器访问https://master:8088 或者https://master:50070 查看 Hadoop 服务状态.
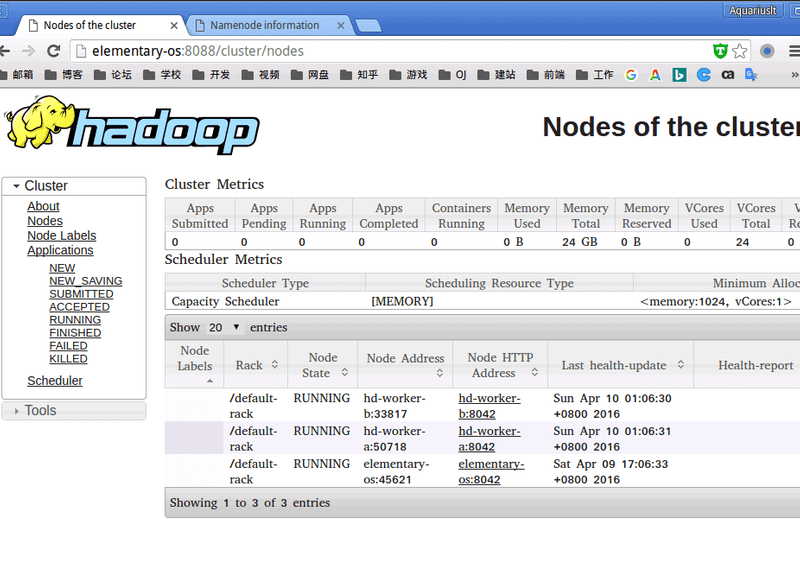
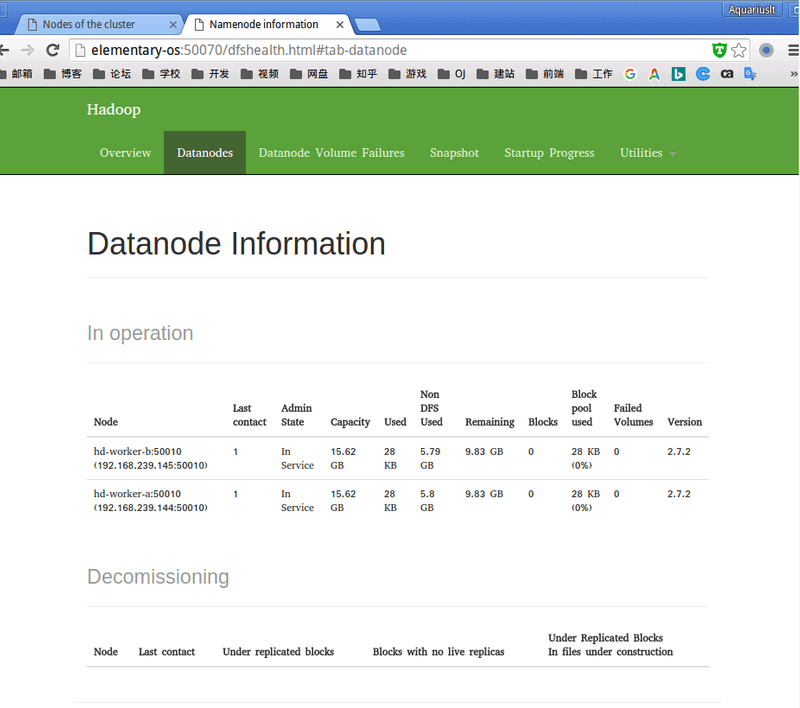
P.S.关于jps命令. jps 位于 jdk 的 bin 目录下,其作用是显示当前系统的 java 进程情况,及其 id 号. jps 相当于 linux 进程工具 ps,但是不支持管道命令 grep jps 并不使用应用程序名来查找 JVM 实例.
Trouble Shooting
防跌坑指南. 记录了在 Hadoop 环境搭建过程中所遇到的坑
Number of Live DataNode:0
通过start-dfs.sh启动了 hadoop 多个节点的 datanode, 且通过jps命令能够看到正常的 datanode 和 resourcemanager 进程, 为什么 live datanode 数目为 0,或者只有 master 的那个 datanode?
可通过以下方法排除:
- 关闭所有节点的防火墙(ubuntu): 先查看防火墙状态
$ sudo ufw status
如果不是 disabled,则禁用
$ sudo ufw disable
- 在 hadoop 服务运行的时候,关闭 namenode 的安全模式
$ hadoop dfsadmin -safemode leave
- 在关闭 hadoop 服务的情况下,删除所有的日志文件,存储文件并重新 format 确保
hadoop_store文件夹下的所有文件夹权限都是 777
$sudo rm -r /usr/local/hadoop/logs
$sudo rm -r /usr/local/hadoop_store/tmp
$sudo rm -r /usr/local/hadoop_store/hdfs
$sidp hdfs namenode -format
References
在环境搭建的过程中,参考了以下两篇文章: 其中 Apache 的官方 Wiki 文档写的真难读. 建议直接先看一遍 aws 的指南再动手.
https://wiki.apache.org/hadoop/GettingStartedWithHadoop https://rstudio-pubs-static.s3.amazonaws.com/